About JVM Warm up
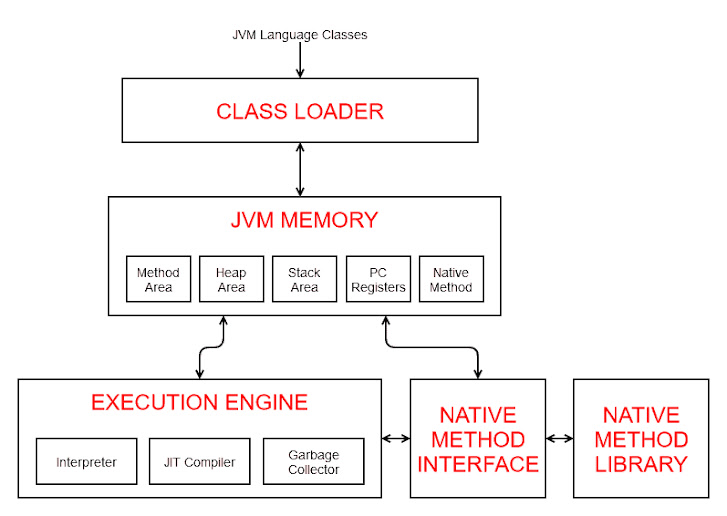
Class Loading JVM 프로세스가 시작하면, 필요한 모든 클래스들은 클래스로더가 세가지 단계를 거쳐 메모리로 로드 한다. 이 과정은 lazy loading 기반으로 동작한다. - Bootstrap Class Loading: Bootstrap Class Loader 가 Java Class 들을 올린다. java.lang.Object 와 같이 JRE/lib/rt.jar 에 있는 필수적인 클래스를 올린다. - Extension Class Loading: ExtClassLoader 는 java.ext.dirs 경로에 있는 모든 JAR 파일들을 책임진다. ㅎGradle 혹은 Maven 기반 application 이 아닌, 개발자가 수동으로 추가한 JAR 들이다. - Application Class Loading: AppClassLoader 가 application class path 에 있는 모든 클래스들을 올린다. Execution Engine Java 는 Interpret 과 Compile 을 모두 사용하는 Hybrid 이다. Java code 를 javac 를 통해서 컴파일하면 platform 독립적인 bytecode 로 변환된다. 이를 실행 시 JVM 은 runtime 에 interpret 통해서 native code 로 실행한다. Just-In-Time Compiler 는 runtime 에 자주 실행되는 코드(method 전체)를 native code 로 compile 한다. 이후에 재실행 시 바로 compiled 된 native code 를 사용한다. 이를 hotspot 이라 부른다. C1 - Client Compiler 빠른 시작과 좋은 반응 속도에 중점을 두고 있다. 최적화 수준은 C2 에 비해 낮지만 컴파일 시간이 짧아 초기 실행 속도를 빠르게 하여 사용자에게 더 빠른 반응을 제공할 수 있다. 복잡하지 않은 최적화로 짧은 시간에 코드를 컴파일하여, 어플리케이션이 빨리 실행될 수 있도록한다. C2- Server ...

.png)

.png)
