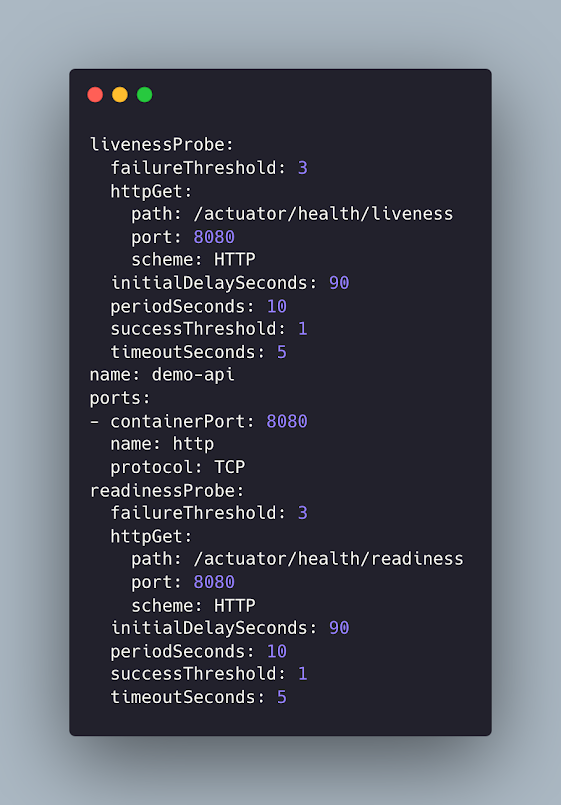
Spring Boot 를 사용하여 서버 어플리케이션을 개발하고 Kubernetes 상에서 운영할 때 Container 의 상태를 확인하고 복구가 불가능한 경우 재시작 시켜야 되는지 알 필요가 있다. 또한 Container 가 트래픽을 받아들일 준비가 되었는지 상태를 알아야한다. 이때 각각 liveness, readiness probes 를 사용한다. 아래와 같이 Kubernetes deployment 에 liveness 와 readiness probes 를 설정한다. initialDelaySeconds 는 Container 가 실행되고 90초 이후에 설정된 path 에 Get 요청을 통해서 정상상태를 확인한다. 200 ~ 399 status code 를 5초이내에 응답 받으면 성공으로 확인한다. periodSeconds 는 10초 주기로 확인한다. 연속해서 3번 비정상 응답을 받을 경우 liveness 는 실패로 돌아가고 Kubelet 은 Container 를 재시작시킨다. 이번엔 Spring Boot 어플리케이션을 보자. gradle 을 사용할 때 아래와 같이 의존성을 추가한다. 그리고 application.yaml 에 아래와 같이 설정한다. 유의해야할 점은 exposure.include 에 * 를 쓰게되면 불필요한 정보가 모두 노출되어 보안에 취약해진다. 예를 들어, heapdump 또는 shutdown 같은 기능을 노출하게 되면 외부에서 공격점이 될 수 있다. /actuator path 요청시 아래와 같이 응답을 받는다. exposure 에 health, info 만 설정해서 두가지만 확인할 수 있다. /actuator/health 를 확인해보자. endponint.health.probes.enabled=true 로 설정해서 liveness, readiness 를 지원한다. /actuator/health/liveness 와 /actuator/health/readiness 를 확인해보자. spring boot application 에...
Topics 데이터베이스에서 테이블과 비슷한 개념으로 특정한 stream of data 으로 구성된다. 원하는 만큼 생성할 수 있고, 이름으로 토픽을 식별한다. 모든 데이터 형식을 지원한다. - json - avro - text - binary 카프카 프로듀서가 데이터를생산하고, 카프카 컨슈머가 데이터 읽는다. Partitions & Offsets 토픽은 여러개의 파티션으로 구성된다. 메세지는 파티션내에서 순서대로 저장된다. 토픽 레벨에서 메세지 순서를 보장하지 않는다. 각각 메세지는 파티션내에서 증분 id 를 가지고 이를 kafka partition offsets 이라 한다. 따라서 offset 은 특정 파티션내에서만 의미를 갖는다. 카프카 토픽은 immutable 이다. 한 번 파티션에 데이터가 쓰여지면 변경이 불가능하다. 데이터는 정해진 시간내에서만 존재한다. 기본값은 1주일이다. 프로듀서에서 데이터에 key 를 지정하지 않으면 랜덤으로 파티션에 할당된다. 파티션 개수는 원하는 만큼 지정할 수 있다. Producer 데이터를 토픽에 쓰는 역할을한다. 프로듀서에서 어느 토픽에 어느 파티션에 데이터를 쓸 지 정할 수 있다. Producer Message Key 프로듀서는 메세지를 key 와 함께 전송할 수 있다. key 가 null 이면 라운드로빈 방식으로 파티션에 데이터가 전송된다. 해싱 전략(murmur2)으로 항상 동일한 파티션으로 할당할 수 있다. - key - binary (can be null) - value - binary (can be null) - compression type (none, gzip, snappy, lz4, zstd) - headers (optional) - key value - partition + offset - timestamp (system or user set) Kafka Message Serializer 카프카는 프로듀서로부터 그리고 컨슈머로 bytes 만 input 과 ou...
생산성을 위해서 여러 프로젝트에서 반복적으로 사용되고 있거나 앞으로 사용될 프로젝트 코드를 효과적으로 관리하기 위해서 라이브러리로 관리하는 방법을 선택할 수 있다. 그렇다면 라이브러리를 어떻게 관리하는 것이 좋을까? java, kotlin 을 사용하여 개발을 할 경우, maven, gradle 을 통해서 의존성을 관리한다. 이 때 의존성들의 저장소는 Maven Central 혹은 jCenter(현재는 지원 중단) 처럼 공개 레포지토리일 수도 있고, 단체에서만 사용하는 사설 레포지토리일 수도 있다. 이러한 레포지토리를 지원하는 여러 툴이 있다. Maven Central 에서 아티팩트를 올리기 위해서는 요건이 엄격하다. 따라서 JitPack 을 사용하여 찍먹해보겠다. 먼저 github 레포지토리 2개를 판다. 하나는 라이브러리용이고, 나머지는 라이브러리를 사용한다. 라이브러리 : https://github.com/ndgndg91/hello-jitpack 아래는 build.gradle.kts 파일이다. maven-publish 플러그인을 사용해야 하며, publishing 을 설정해야한다. 아래는 재사용할 코드를 간단하게 작성해보았다. 그리고 git tag 를 통해 버전을 관리한다. https://github.com/ndgndg91/hello-jitpack/releases/tag/0.0.2 사용할 라이브러리를 작성하고 git tag 를 땄으면 1차 준비는 완료했다. 다음은 https://jitpack.io 에 가서 내가 작성한 github repository 를 검색한다. 0.0.2 이라는 git tag 를 확인할 수 있다. 그리고 build Log 를 확인할 수 있다. 여기까지 성공했다면 다음은 쉽다. https://jitpack.io/com/github/ndgndg91/hello-jitpack/0.0.2/build.log 사용: https://github.com/ndgndg91/use-jitpack build....
이번글에서는 프로그래밍에서 멱등성에 대해 정리하고 실제 상황에서 어떻게 구현해야지 멱등성을 달성할 수 있는지 작성하겠다. 멱등성이란? 영어로는 idempotent. 사전적 정의로는 "연산을 여러 번 적용하더라도 결과가 최초 실행 결과가 그대로 보존되는 성질을 의미" 이다. 실제 서비스에서 일어날 수 있는 상황에 멱등성을 통해서 해결해보자. 고객이 아마존이나 쿠팡에서 상품을 구매하려고 한다. 고객은 상품을 구매하기 위해서 결제를 해야 한다. 이 때 결제는 두 번 이상 실행되어서는 절대 안된다. 1. 일명 "따닥" 으로 고객이 버튼을 빠르게 두 번 클릭하는 상황이 발생할 수 있다. 2. 고객이 첫번째 결제 요청을 하고 실제로 결제가 처리되었지만 네트워크 오류로 응답이 전달되지 못하여 고객이 버튼을 다시 클릭하는 상황이 발생할 수 있다. 만 원을 결제했는데, 실제 2만원이 결제되는 최악의 상황은 발생하지 않아야 한다. 데이터베이스 고유 키 제약조건 (unique key constraint) 1. 결제 요청을 받으면 테이블에 새 레코드를 넣으려고 시도한다. 2-1. 새 레코드 추가에 성공했다면 이전에 처리한 적이 없는 결제 요청이다. 2-2. 새 레코드 추가에 실패했다면 이전에 받은 적이 있는 결제 요청이다. 이러한 중복 요청은 처리하지 않는다. 일회성 토큰 Nonce(Number used Only Once) UUID 또는 timestamp 와 같은 값을 사용하여 정확히 한 번만 사용할 수 있는 장치를 마련한다. 행위에 대한 혹은 도메인(결제)에 대한 식별자 역할을 한다. 이미 처리된 동일한 Nonce 값이 들어온 경우 중복 요청으로 간주하고 처리하지 않는다. 이 때 한 가지 고려할 점은 이 값을 서버에서 제공하여 일회용 토큰으로써 사용하는 것이다. 클라이언트에서 값을 받는것은 언제든지 위조 될 수 있기 때문이다. 간단한 예제 코드 UUID 일회용 결제 토큰을 Redis 를 활용하여 사용 여부를...
G1 GC 소개 Java7 부터 사용이 가능했고, Java9 부터 기본 GC 로 선정되었다. G1 GC 는 큰 메모리를 사용하는 멀티 프로세스 머신에 적합한 GC 이다. 설정된 목표 stop the world 시간을 높은 확률로 달성하려고 시도한다. 최대한 정지 시간을 예측 가능하고 짧게 유지하려는 목적이다. 높은 처리량을 목표로 하고 있으며, 사용자의 설정 필요성을 최소화하려고 한다. 개발자가 성능을 최적화하기 위해 많은 시간을 소비하지 않도록 하는것을 목표로 한다. 적용 대상으로는 - heap 크기가 수 GB ~ 최대 10GB 환경 - 실시간으로 객체 할당 및 프로모션 비율이 크게 변할 수 있는 환경 - heap 내에서 상당한 수준의 조각화(fragmentation)가 발생할 수 있는 환경 - 수백 밀리초를 넘지 않는 예측 가능한 stop the world 시간 목표가 필요한 경우 CMS(Concurrent Mark-Sweep) GC 을 대체한다. heap 을 여러 영역으로 나누고, 가비지 컬렉션을 수행하는 동안 영역들을 동시에 처리하여 고성능을 달성하고자 한다. G1 GC 활성화 기본 GC 로 별도의 설정이 필요하지는 않다. 명시적으로 -XX:+UseG1GC 통해 가능하다. 기본 개념 G1 도 다른 GC 와 마찬가지로 young generation, old generation 으로 메모리 생명주기에 세대 개념을 사용한다. 그리고 여러 스레드를 사용하여 점진적으로 가비지 컬렉션을 수행한다. 처리량 개선을 위해서 일부 가비지 컬렉션 작업은 어플리케이션이 실행중에도 진행할 수 있으며 일부 중요한 작업은 stop the world 를 발생시킨다. Heap Layout G1은 힙을 동일한 크기의 힙 영역 집합으로 분할하고, 각 영역은 인접한 범위의 가상 메모리로 구성된다. 영역은 메모리 할당 및 메모리 회수의 단위이다. 언제든지 영역은 비어있거나, young generation, old generation 으로 할당 할 수 있다. 메모리 요청이...
Z Garbage Collector JDK 11 에서 실험적인 기능으로 소개했다. JDK 15 에서 정식으로 출시 되었다. 물론 JDK 21에서도 사용할 수 있다. ZGC 어플리케이션 스레드 실행을 10ms 이상 중단하지 않고 고비용 작업을 동시에 수행한다. 지연 시간은 힙 사이즈와 무관하며, 몇백 MB의 작은 힙부터 16테라의 매우 큰 힙을 사용해도 잘 작동하낟. JDK 11 에서 JDK 15 이하 버전에서는 -XX:+UnlockExperimentalVMOptions 와 -XX:+UseZGC 옵션을 동시에 사용하여 활성화한다. JDK 15 이상 버전에서는 -XX:+UseZGC 하나의 옵션으로 사용할 수 있다. 아래의 핵심 기능을 사용하며 ZGC 또한 G1 GC 와 마찬가지로 concurrent 가비지 컬렉터이다. Concurrent Region-based Compacting NUMA-aware Using colored pointers Using load barriers Using store barriers (in the generational mode) Configuration & Tuning ZGC 도 G1 GC 와 유사하게 최소한의 설정을 필요로 하며, 어플리케이션이 실행하는 과정에서 스스로 적응하는 기능이 있다. ZGC 은 동적으로 세대를 리사이징하고, GC 스레드수도 조절하며, tenuring thresholds 도 조절한다. 주요 튜닝 포인트는 최대 힙 사이즈를 늘리는 것이다. (-Xmx) ZGC 는 generational version 과 non-generational version 이 있는데 non-generational version 은 레거시이며, 실행중에 세대 개념을 사용하지 않는다. JDK 21부터 최신 버전인 generational version 이 출시 되었으며 최신 버전 사용을 권장한다. generational version 은 -XX:+UseZGC 옵션과 -XX:+ZGenerational 옵션을 사용한다....
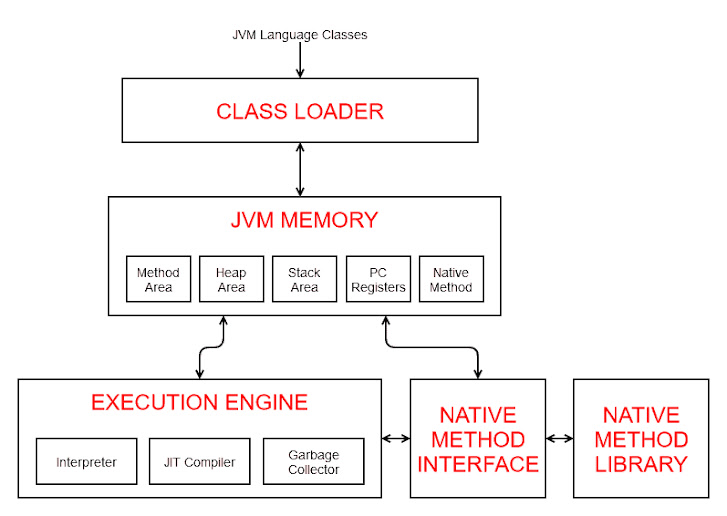
Class Loading JVM 프로세스가 시작하면, 필요한 모든 클래스들은 클래스로더가 세가지 단계를 거쳐 메모리로 로드 한다. 이 과정은 lazy loading 기반으로 동작한다. - Bootstrap Class Loading: Bootstrap Class Loader 가 Java Class 들을 올린다. java.lang.Object 와 같이 JRE/lib/rt.jar 에 있는 필수적인 클래스를 올린다. - Extension Class Loading: ExtClassLoader 는 java.ext.dirs 경로에 있는 모든 JAR 파일들을 책임진다. ㅎGradle 혹은 Maven 기반 application 이 아닌, 개발자가 수동으로 추가한 JAR 들이다. - Application Class Loading: AppClassLoader 가 application class path 에 있는 모든 클래스들을 올린다. Execution Engine Java 는 Interpret 과 Compile 을 모두 사용하는 Hybrid 이다. Java code 를 javac 를 통해서 컴파일하면 platform 독립적인 bytecode 로 변환된다. 이를 실행 시 JVM 은 runtime 에 interpret 통해서 native code 로 실행한다. Just-In-Time Compiler 는 runtime 에 자주 실행되는 코드(method 전체)를 native code 로 compile 한다. 이후에 재실행 시 바로 compiled 된 native code 를 사용한다. 이를 hotspot 이라 부른다. C1 - Client Compiler 빠른 시작과 좋은 반응 속도에 중점을 두고 있다. 최적화 수준은 C2 에 비해 낮지만 컴파일 시간이 짧아 초기 실행 속도를 빠르게 하여 사용자에게 더 빠른 반응을 제공할 수 있다. 복잡하지 않은 최적화로 짧은 시간에 코드를 컴파일하여, 어플리케이션이 빨리 실행될 수 있도록한다. C2- Server ...
문제링크 : https://www.hackerrank.com/challenges/between-two-sets/problem You will be given two arrays of integers and asked to determine all integers that satisfy the following two conditions: The elements of the first array are all factors of the integer being considered The integer being considered is a factor of all elements of the second array These numbers are referred to as being between the two arrays. You must determine how many such numbers exist. For example, given the arrays and , there are two numbers between them: and . , , and for the first value. Similarly, , and , . Function Description Complete the getTotalX function in the editor below. It should return the number of integers that are betwen the sets. getTotalX has the following parameter(s): a : an array of integers b : an array of integers Input Format Th...
첫 번째 에러 ! ora7nt.dll 라이브러리 어쩌구 저쩌구 한다. 본인은 구글링을 해본 결과 erwin이 32bit만 지원하니까 64bit 오라클을 설치했으면 지우고 32bit를 재설치하고 해보라는 답글들을 많이 봤는데 64bit문제가 아니였다. 왜냐면 내 친구가 오라클을 64bit 설치했는데 erwin이랑 잘만 연결이 되었다. 따라서 32, 64bit 개같은 소리는 듣지 않기로 하고 다른 방법을 찾아보니까 시스템환경변수에서 PATH에 oracle client를 지정해주지 않아서라는 답을 얻었다. 위에 에러 메세지에서도 적절한 클라이언트 소프트웨어를 설치하라고 한다. 그래서 PATH설정을 해주니 ora7nt.dll에러는 해결 되었다. 하지만 다음 에러에 봉착했다! ORA-01041 에러 구글링 해본 결과 아래 링크에 답이 나와있었다. https://erwinhelp.zendesk.com/hc/en-us/articles/230410267-Receiving-Error-ORA-01041-internal-error-hostdef-extension-doesn-t-exist-on-re-establishing-a-connection-to-Oracle- Locate the 'sqlnet.ora' file and set: SQLNET.AUTHENTICATION_SERVICES = (NONE) 위 처럼 sqlnet.ora 파일에서 설정을 변경해주니까 연결이 잘되었다. 잘 되는 모습, 먼저 forward Engineer 그 다음은 preview





 앞뒤 그리고 옆면 찍어보기 ㅋㅋ
앞뒤 그리고 옆면 찍어보기 ㅋㅋ






.png)


.png)


댓글
댓글 쓰기