Java - HashMap (feat. LinkedList, Tree.. maybe Later)
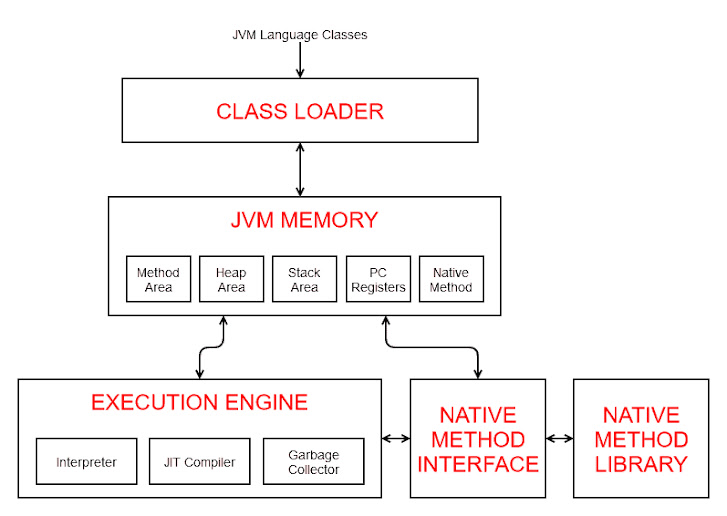
지난 글에서는 ArrayList 를 까보면서 native 메서드에 대해 잠시 다루어보았다.






이번 글에서는 직접 HashMap 을 구현해보도록 하겠다.
JDK 를 까보면서 그리고 여라 다른 블로깅을 참고하면서 내 방식으로 구현해 보았다.
https://medium.com/@mr.anmolsehgal/java-hashmap-internal-implementation-21597e1efec3
https://www.devglan.com/java8/hashmap-custom-implementation-java
https://d2.naver.com/helloworld/831311
https://www.devglan.com/java8/hashmap-custom-implementation-java
https://d2.naver.com/helloworld/831311
우선, 핵심을 먼저 정리하고 작성해보겠다.
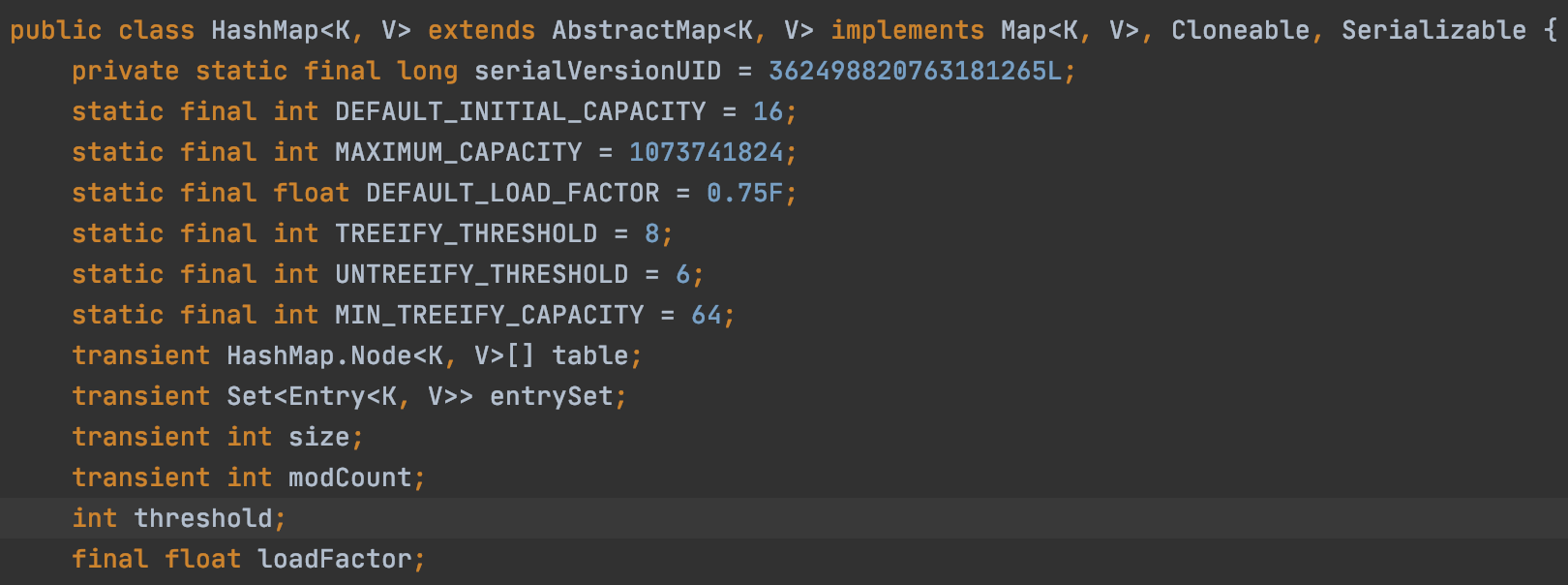
HashMap 은 Key Value 저장소이다. 분할상환방식에 의해서 get() put() 메서드는 상수 시간의 시간복잡도 O(1) 을 가진다.
HashMap 은 내부적으로 key, value 를 지닌 Node 의 배열을 가진다. Node 의 개념과 일치하는 class 는 Entry<K, V> class 이다. HashMap 은 get(), put() 메서드 호출 시 객체의 hashcode 를 통해 index 를 계산하고 Node 배열의 Node 를 배치시킨다.

그렇다면 같은 index 를 가지는 객체들은 어떻게 관리를 할까? 바로 LinkedList 를 배열의 index 마다 가지며, 2차원 형태의 테이블을 이루게 된다.
아래는 JDK 11 버전의 HashMap 을 직접 까보았다. 아래와 같이 Node 는 Map.Entry<K, V> interface 를 구현하고 있다. 그리고 필드로는 hash, key, value, 그리고 LinkedList 이기에 next 를 가진다.

여기까지가 HashMap 가장 기본적인 원리이다. 하지만 가장 큰 문제가 있다. 바로 다른 객체가 동일한 hashcode 를 가질 때 이다.
예를 들어, 아래와 같이 Developer class 를 작성했다. equals() 와 hashCode() 메서드를 확인해보자.
name, age, sex, language 가 모두 동일할 경우 바로 같은 hashCode 를 가지게 된다.
ndg 와 ndg2 는 서로 다른 객체이다. new 연산자를 통해서 생성했기 때문에, 내부 필드의 값은 같지만 결론적으로 다른 주소를 가진다. 따라서 다른 객체이다. 하지만 Developer 의 hashCode() 메서드는 내부의 필드가 같으면 같은 hashcode 를 생성한다. HashMap 에 담는 데이터가 증가할 수록 일어날 수 있는 확률이 높아지기 때문에 hash 전략은 매우 중요하다.


그 다음에 중요한 개념으로 LOAD_FACTOR 개념을 들 수 있다. 아래 JDK 11 에서 확인할 수 있듯이 Default 는 0.75 이다. 이는 무슨 숫자일까?
이는 HashMap 크기를 증가시킬 때 언제 증가시켜야 하는지를 알려주는 임계점이다.
0.75 는 3/4 로 현재 HashMap 에 3/4 가 채워졌을 경우, HashMap 의 크기를 증가시켜야 하는지 알려주는 수치이다.

아래의 resize() 함수를 확인해보자. Node array 의 사이즈를 증가시키는 메서드이다.
내부에서 resize() 메서드를 여러군데에서 호출하고 있어서 각각의 디테일은 전부 캐치하지 못했지만,
내가 파악한 요지는 이전 배열의 크기를 loadFactor 에 따라서 Capacity 를 통해 계산하고 있다.

이번 글은 여기서 마무리하도록 하겠다.
내부적으로 LinkedList 이외에 Tree 를 사용하고 있는데 이는 더 공부하고 정리를 해보도록 하겠다.
자료구조를 다시 공부하면서 여러모로 기본에 더 충실할 필요를 느꼈다.
.png)


.png)


댓글
댓글 쓰기